Email-based security threats are evolving at a breakneck pace. Our system must work faster and smarter to identify new phishing techniques and protect our customers from advanced attacks designed to bypass existing security measures. Meanwhile, we must keep our costs down to deliver an ROI-friendly solution.
But scaling up our technical processes is easier said than done: On the busiest days, Tessian processes more than 1,400 data transactions per second, with some event payloads reaching 200MB. We encountered growing pains as our customer base grew, and our technology must adapt.
Let’s look under the hood to see how our engineering team overcame a data challenge by adopting and refining the right solution to enhance performance cost-effectively and better protect our customers.
The Challenge: Small files caused big problems
Processing over a thousand data transactions per second with sizable payloads is far from a stroll in the park. Initially, we stored the information extracted from these files in a relational RDS PostgreSQL database as part of our production flow for updating email statistics and flagging malicious events.
However, when we used the data in different ways, like ad-hoc querying, model training, or big-batch job processing, we created substantial load on the database—slowing down processes and impacting overall performance.
To avoid issues, we created and queried a version of the database in Amazon S3 by creating a workflow to update the database and push a message to a Kafka queue. We then stream from that queue to an S3 bucket to create a replica of events in our datasets.
The inherent nature of this architecture created delays. For example, input could arrive days or weeks after the original email event if a client was away from their mailbox for a long time (e.g., on vacation) or we had to wait for customers to provide feedback on whether we flagged an email correctly.
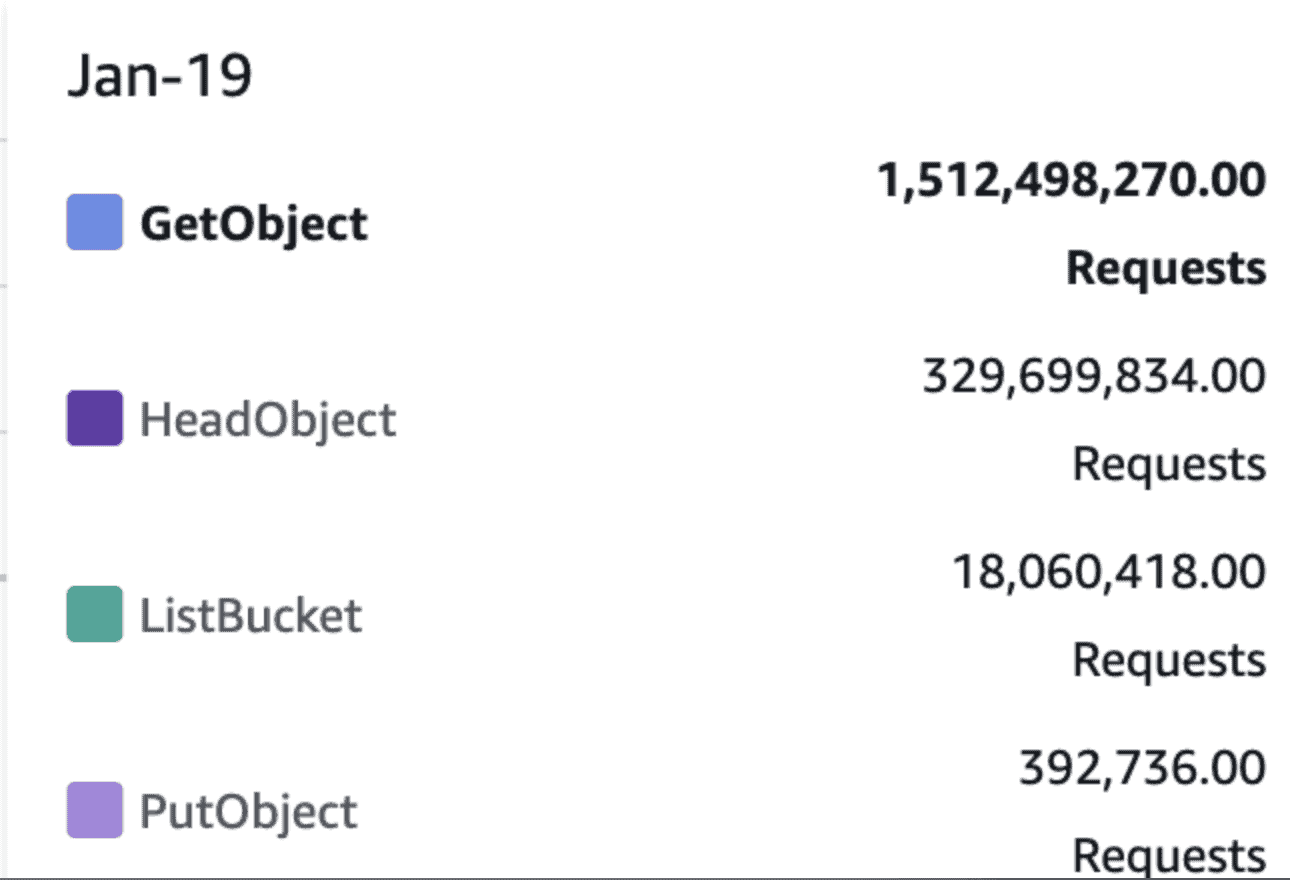
While these late incoming events required just a simple update in our system’s Postgres database table, they pose a big challenge for the S3 version. The updates created numerous small files, increasing the querying time substantially. We handled a maximum of 1.5 billion “GetObject” requests daily, affecting the system’s performance.
Exploring options: Why we chose Apache Iceberg
We explored various ways to solve the challenge of handling small files from late-arriving events:
Option 1: Change our data layout logic to accommodate late incoming events and reduce the number of small files by batching incoming events based on dates. However, this method would affect performance because the system needs to scan many files in the dataset to query for the event origin date.
Option 2: Create a process to compact and bundle small files. However, we’d need to solve the issues of files being written concurrently to our s3 datasets and devise a method to update our datasets while eliminating duplicates and partial results from queries.
After analyzing our options, we decided to introduce an off-the-shelf table format that could support our requirements, and we landed on Apache Iceberg.
Wait… What is Apache Iceberg?
Apache Iceberg is a high-performance, open-source table format for handling massive analytic tables or large datasets in data lakes. It simplifies data processing on petabyte-scale tables and offers various advantages over legacy formats.
For example, the metadata layer improves query planning, allowing us to manage, track, and organize all the data sources that feed into a table. Plus, it’s highly scalable and enables fine-grained data management. You can perform schema evolution, ACID transactions, and data update or deletion—treating your data lake as database tables to increase cost-efficiency.
The learning curve: Applying Iceberg to our system
For the first iteration of the implementation, we created a Spark-structured streaming job to consume events from a Kafka queue and update an Iceberg table. Concurrently, we set up Iceberg metadata jobs to run once a day to perform the following:
- Data compaction: Condense small files in a partition into one or a few files to meet our size goal.
- Metadata compaction: Consolidate and repartition the metadata to improve query speed.
- Data expiry: Delete old snapshots of the data and metadata.
This out-of-the-box approach worked initially. However, issues related to failures in reading the Avro metadata files (e.g., failed queries and metadata jobs) arose after we migrated one of our biggest tables to the flow. We experienced symptoms of network errors when loading the Avro metadata.
Instead of treating the symptoms, our engineers knew they must get to the root cause to ensure our system’s stability and reliability. We investigated the metadata and found that even after a compaction operation, we had 12k manifest fields and 150 GB of metadata. The size would likely cause queries and metadata operations to fail.
We quickly realized the metadata issue occurred because we underestimated how much late-arriving data hit our system. When we sampled the data, we noticed constant updates to old partitions, resulting in numerous small files in some of them, impacting system performance and causing errors.
Making it work: Solving the Iceberg metadata challenge
We must streamline our metadata to ensure our tables’ efficiency and reliability. So, we made the following improvements:
- We ran data compaction jobs continuously. Instead of targeting only data from the past two days, where we assumed most of the small files originated, we triggered compaction jobs to condense the largest 1,000 partitions to reduce the number of manifest files and the amount of metadata.
- Since the number of metadata files is directly related to the number of partitions, the metadata compaction job should create a manifest file that points to one partition only. Inside the builtin iceberg compaction jobs, the number of metadata files could be impacted by the total size of the metadata and the target manifest file’s size. We tweaked the manifest target size to reduce the number of files of metadata written to make sure we keep one file for a partition.
- Iceberg defaults to storing statistics on the first 100 columns in a schema. However, we don’t need statistics on most columns because our queries are limited to a subset. We decreased the number of columns for which we stored statistics to reduce the number of metadata files.
- We set Iceberg to use manifest inheritance by default to avoid rewriting all the manifest files for every operation to avoid large metadata file sizes and potential operation failures.
- We changed the underlying http client library to use the apache-http client instead of the url connection http client which reduced the network errors we encountered and made the jobs that worked with Iceberg much more stable.
We created a dataset with substantially less data and metadata, leading to a much smaller overall metadata size. The changes improved our data query performance and the resilience of our metadata operations.
Protecting our customers with robust analytics
Our decision to implement Apache Iceberg allows us to analyze vast amounts of data faster and at lower costs to stay ahead of emerging threats. Our data scientists and engineers can build models quickly, develop new processes, and build more robust features. It allows us to scale our infrastructure to deliver more reliable services to our current users while paving the way to grow and serve more customers for years to come.
Zohar Stiro and Jake Kavanagh