In recent years, we’ve heard the term “Offensive AI” being used more frequently to describe a new type of cyber threat – one that sees cybercriminals using artificial intelligence (AI) to supercharge their cyber attacks, advance impersonation scams, and avoid detection.
In response, organizations are being advised to “fight fire with fire” and invest in defensive AI solutions in order to stay ahead of the bad guys, a sort of modern day “spy on spy” warfare tactic.
Sure, cybercriminals are using more sophisticated technologies to advance their attack campaigns, but let’s start by getting one thing straight: where we are at the moment is not “AI”. For a system to be considered intelligent, it needs to exhibit autonomous behavior and goal seeking.
What we are seeing, though, is an emerging use of Machine Learning (ML) and adaptive algorithms, combined with large datasets, that are proving effective for cybercriminals in mounting attacks against their targets.
Semantics, I know.
But it’s important that we manage the hype. Even the washing machine I just purchased says it includes “AI” functionality. It doesn’t.
Organizations do, though, need to be aware of attackers’ use of offensive ML, and every company needs to understand how to defend itself against it. I can help.
So, what is offensive ML?
At this stage, offensive ML is often the use of ML and large data-lakes to automate the first stages of cyber attacks. In particular the reconnaissance, weaponization, and delivery stages of the Cyber-Kill-Chain lend themselves to automation.
It allows attacks to be carried out on a much larger scale and faster than ever previously seen. It also helps attackers overcome their human-resource problem—yes, even cybercriminals have this problem; skilled cyber staff are hard to find.
Automation frees up the human’s time, keeping them involved for the later stages of an attack once a weakness that can be exploited has been found. To a large degree, many cyber attacks have become a data science issue, as opposed to requiring stereotypical ‘elite hackers’.
A good offensive ML will also have a feedback mechanism to tune the underlying models of an attack, for example, based on the success of a lure in front of a potential victim in a phishing attack. The models will start to favor successful approaches and, over time, increase in efficiency and effectiveness.
How is offensive ML being used today?
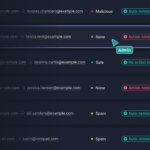
One example of offensive ML I’ve observed is large-scale scanning of perimeter systems for fingerprinting purposes.
Fingerprinting the perimeter of organizations – assigning IP addresses with organizations, public data (DNS, MX lookup) and industry sectors – is a simple data-management issue. However, if this is combined with Common Vulnerabilities and Exposures (CVE) updates, and possibly dark web zero-day exploits, it provides attackers with a constantly updated list of vulnerable systems.
You can learn more about zero-day vulnerabilites here: What is a Zero-Day Vulnerability? 3 Real-World Examples.
Organizations defending themselves against cybercrime frequently have to go through a time consuming testing process before deploying a patch and, in some cases, the systems are just not patched at all. This gives an attacker a window of opportunity to deploy automated scripts against any targets that have been selected by the ML as meeting the attack criteria. No humans need be involved except to set the parameters of the attack campaign: it’s fully automated.
An attacker could, for example, have the ML algorithms send emails to known invalid email addresses at the target organization to see what information or responses they get—Do the email headers give clues about internal systems and defenses? Do any of the systems indicate unpatched vulnerabilities?
They can use ML to understand more about the employees they will target too, crawling through social media platforms like LinkedIn and Twitter to identify employees who recently joined an organization, any workers that have moved roles, or people that are dissatisfied with their company. Why? Because these people are prime targets to attempt to phish.
Combining this information is step one. Attackers then just need to understand how to get past defenses so that the phishing emails land into a target employee’s inbox.
MX records – a mail exchanger record that specifies the mail server responsible for accepting email messages on behalf of a domain name – are public information and would give the ML information as to what Secure Email Gateway (SEG) a company is using so that an attacker could tailor the lure and have the most chance of getting through an organization’s defenses.
Another area in which offensive ML proves problematic for organizations is facial recognition.
Attackers can deploy ML technology or facial recognition to match company photos with photos from across the Internet, and then build up a graph of relationships between people and their target. An exercise in understanding “who knows who?”.
With this information, bad actors could deploy social media bots under ML control to build trust with the target and their associates. From public sources, an attacker knows their target’s interests, who they work with, who they live with; all this is gold dust when it comes to the “phishing stage” as an attacker can make the scam more believable by referring to associates, shared interests, hobbies etc.
Using offensive ML in ransomware attacks
There are other reasons to be concerned about the impact offensive ML can have on your organization’s security. Attackers can use it to advance their ransomware attacks.
Ransomware attacks – and any exploits used to deliver the ransomware – have a short shelf-life because defenses are constantly evolving too. Therefore, successful ROI for the attacker depends on whether they choose their targets carefully. Good reconnaissance will ensure resources are used more efficiently and effectively than using a simpler scatter-gun approach.
For any cybercriminal involved in “ransomware for hire”, offensive ML proves invaluable to earning a higher salary. They can use the data gathered above to set their pricing model for their customers. The better defended – or more valuable- the target, the higher the price. All this could be, and likely is, automated.
So, how can organizations protect themselves from an offensive AI/ML attack?
It’s the classic “spy vs spy” scenario; attacks evolve and so do defenses.
With traditional, rule-based defensive systems, though, the defender is always at a disadvantage. Until an attack is observed, a rule can’t be written to counteract it. However, if an organization uses ML, the defensive systems don’t need to wait for new rules; they can react to anomalous changes in behavior autonomously and adjust defensive thresholds accordingly.
In addition, defensive ML systems can more accurately adjust thresholds based on the observed riskiness of behavior within a defender’s organization; there is no longer a need to have a one-size-fits-all defense.
A good ML-based system will adapt to each company, even each employee or department, and set corresponding defense levels. Traditional, rule-based systems can’t do this. In my opinion, the future of defensive security is a data-issue; the days of the traditional human-heavy Security Operations Center are numbered.
What questions should organizations ask to ensure they have the right defenses in place?
- First and foremost, ask your IT service provider why they think their system is actually AI. Because it almost certainly isn’t. If the vendor maintains that they have a real AI solution, be very skeptical about them as a reliable vendor.
- Ask vendors how their system would react to a zero-day exploit: How long would their system need to deal with a novel attack? Would the user need to wait for a vendor update?
- Ask vendors about data and threat sharing. All companies are under reconnaissance and attack, and the more data that is shared about this, the better the defenses. So ask, does the vendor share attack data, even with their competitors?