




In December we successfully flipped around half a billion monthly API requests from our Ruby on Rails application to some new Python 3 applications.
Now that the dust has settled, and we’re comfortable that all has gone well, I wanted to write up the details of the project, give a bit of a history of Engineering at Tessian, and share some lessons learned in the hope that others may benefit from mistakes we’ve made.
In the beginning, there was Rails
Long before Tessian became what it is today, most of our code base for our backend infrastructure was written in Ruby on Rails.
This was the right choice of technology at the time; it allowed us to produce a reliable product while iterating quickly. But as we grew it became apparent that being able to share production code with our data science team (who predominantly work in Python) would allow us to move much more quickly.
That was when we decided to build out some core backend functionality using Python 3. This would allow our backend code to lean heavily on various open source tooling for data science and machine learning.
That decision was made 3 years ago and today, in hindsight, it still looks like the right call. However, and you may be ahead of me already here, deciding to start using Python did not magically get rid of all the Ruby code we had already written.
That was the situation one of our Engineering teams found themselves pondering in August last year.
Deciding to migrate
At Tessian our teams have themes to help define their place in the world. Themes are mini mission statements that ladder up to Tessian’s greater mission to secure the human layer.
One team’s theme is “Tessian’s stellar security reputation aids growth”. Since the team’s inception, they had been focusing on building security features in our Python code, where a lot of backend development and data processing takes place.
While debating the most important thing to work on next, we decided to dig in to some data. This showed that 500,000 API requests an hour were being handled by our Ruby on Rails application server. Looking at that number, coupled with the fact that we had grown the Engineering team 100% in the past year and hired 0 Ruby developers, it quickly became apparent that this part of our code base needed some attention.
The following factors ultimately contributed to our decision:
- The proportion of Ruby experts in the company was depleting.
- Improvements to code linting, security frameworks were getting added to Python and not Ruby.
- Our Ruby app had not kept up with improvements we had made to monitoring and alerting.
- Ruby was the original code base and contained some of the oldest and least well understood code in the company.
- There were some tickets in our backlog around poor performance of some of the Ruby endpoints, meaning future development of them was likely.
So the decision was made: we would port the existing Ruby APIs to our Python code base, allowing them to make use of our latest frameworks and practices.
Path to migration
Given the high volume of traffic and the importance of the APIs we wanted to ensure that we kept risk to a minimum when porting them. With this code came other challenges such as poorly defined interfaces and many different client versions.
After a few whiteboard sessions, we settled on a phased approach that went as follows.
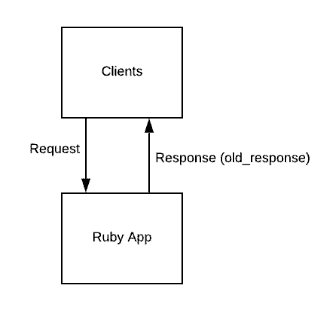
Phase 0 – Existing setup
The original setup – clients talking to our Ruby application.