At Tessian, we have many applications that interact with each other using REST APIs. We noticed in the logs that at random times, uncorrelated with traffic, and seemingly unrelated to any code we had actually written, we were getting a lot of HTTP 502 “Bad Gateway” errors.
Now that the issue is fixed, I wanted to explain what this error means, how you get it and how to solve it. My hope is that if you’re having to solve this same issue, this article will explain why and what to do.
First, let’s talk about load balancing
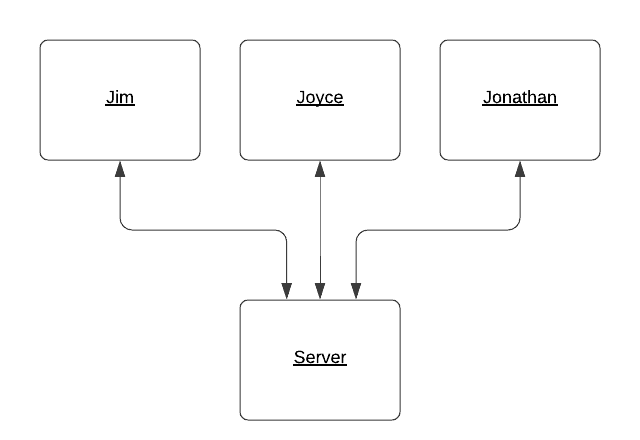
An example of a development system where clients communicate directly with the server.
In a development system, you usually run one instance of a server and you communicate directly with it. You send HTTP requests to it, it returns responses, everything is golden.
For a production system running at any non-trivial scale, this doesn’t work. Why? Because the amount of traffic going to the server is much greater, and you need it to not fall over even if there are tens of thousands of users.
Typically, servers have a maximum number of connections they can support. If it goes over this number, new people can’t connect, and you have to wait until a new connection is freed up. In the old days, the solution might have been to have a bigger machine, with more resources, and more available connections.
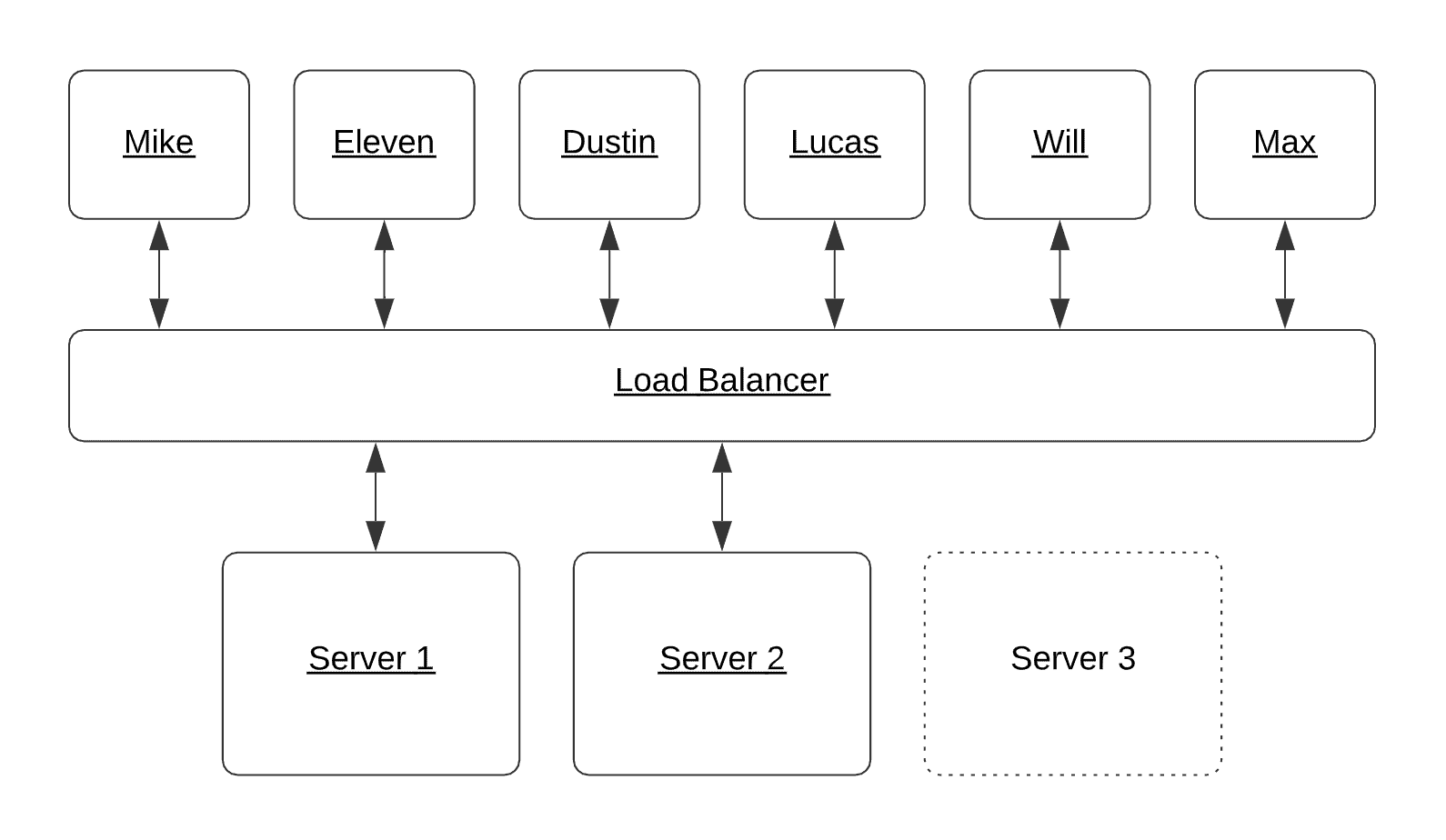
Now we use a load balancer to manage connections from the client to multiple instances of the server. The load balancer sits in the middle and routes client requests to any available server that can handle them in a pool.
If one server goes down, traffic is automatically routed to one of the others in the pool. If a new server is added, traffic is automatically routed to that, too. This all happens to reduce load on the others.
An example of a production system that uses a load balancer to manage connections from the client to multiple instances of the server.
What are 502 errors?
On the web, there are a variety of HTTP status codes that are sent in response to requests to let the user know what happened. Some might be pretty familiar:
- 200 OK – Everything is fine.
- 301 Moved Permanently – I don’t have what you’re looking for, try here instead.
- 403 Forbidden – I understand what you’re looking for, but you’re not allowed here.
- 404 Not Found – I can’t find whatever you’re looking for.
- 503 Service Unavailable – I can’t handle the request right now, probably too busy.
4xx and 5xx both deal with errors. 4xx are for client errors, where the user has done something wrong. 5xx, on the other hand, are server errors, where something is wrong on the server and it’s not your fault.
All of these are specified by a standard called RFC7231. For 502 it says:
The 502 (Bad Gateway) status code indicates that the server, while acting as a gateway or proxy, received an invalid response from an inbound server it accessed while attempting to fulfill the request.
The load balancer sits in the middle, between the client and the actual service you want to talk to. Usually it acts as a dutiful messenger passing requests and responses back and forth. But, if the service returns an invalid or malformed response, instead of returning that nonsensical information to the client, it sends back a 502 error instead.
This lets the client know that the response the load balancer received was invalid.
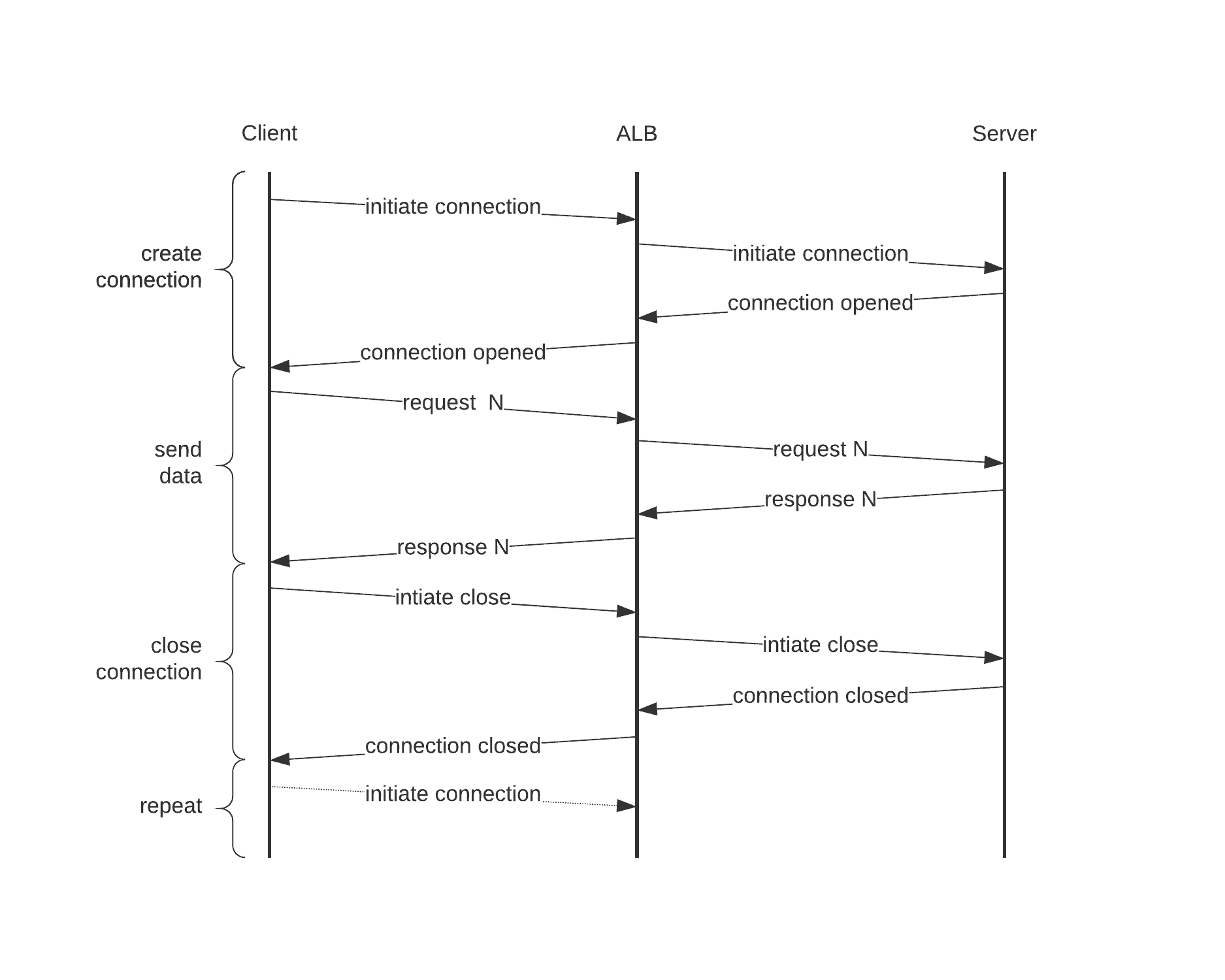
High level overview of requests between the client, the ALB, and the server Created with Lucidchart.
The actual issue
Adam Crowder has done a full analysis of this problem by tracking it all the way down to TCP packet capture to assess what’s going wrong. That’s a bit out of scope for this post, but here’s a brief summary of what’s happening:
- At Tessian, we have lots of interconnected services. Some of them have Application Load Balancers (ALBs) managing the connections to them.
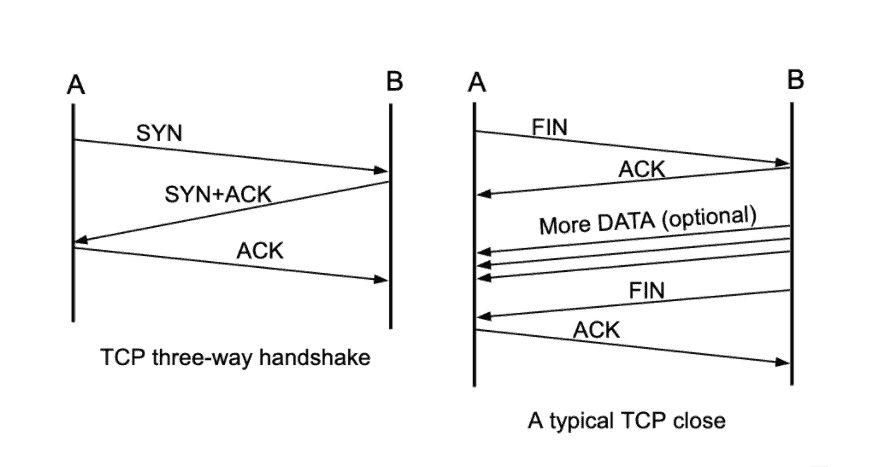
- In order to make an HTTP request, we must open a TCP socket from the client to the server. Opening a socket involves performing a three-way handshake with the server before either side can send any data.
- Once we’ve finished sending data, the socket is closed with a 4 step process. These 3 and 4 step processes can be a large overhead when not much actual data is sent.
- Instead of opening and then closing one socket per HTTP request, we can keep a socket open for longer and reuse it for multiple HTTP requests. This is called HTTP Keep-Alive. Either the client or the server can then initiate a close of the socket with a FIN segment (either for fun or due to timeout).
Source: An Introduction to Computer Networks, edition 1.9.21
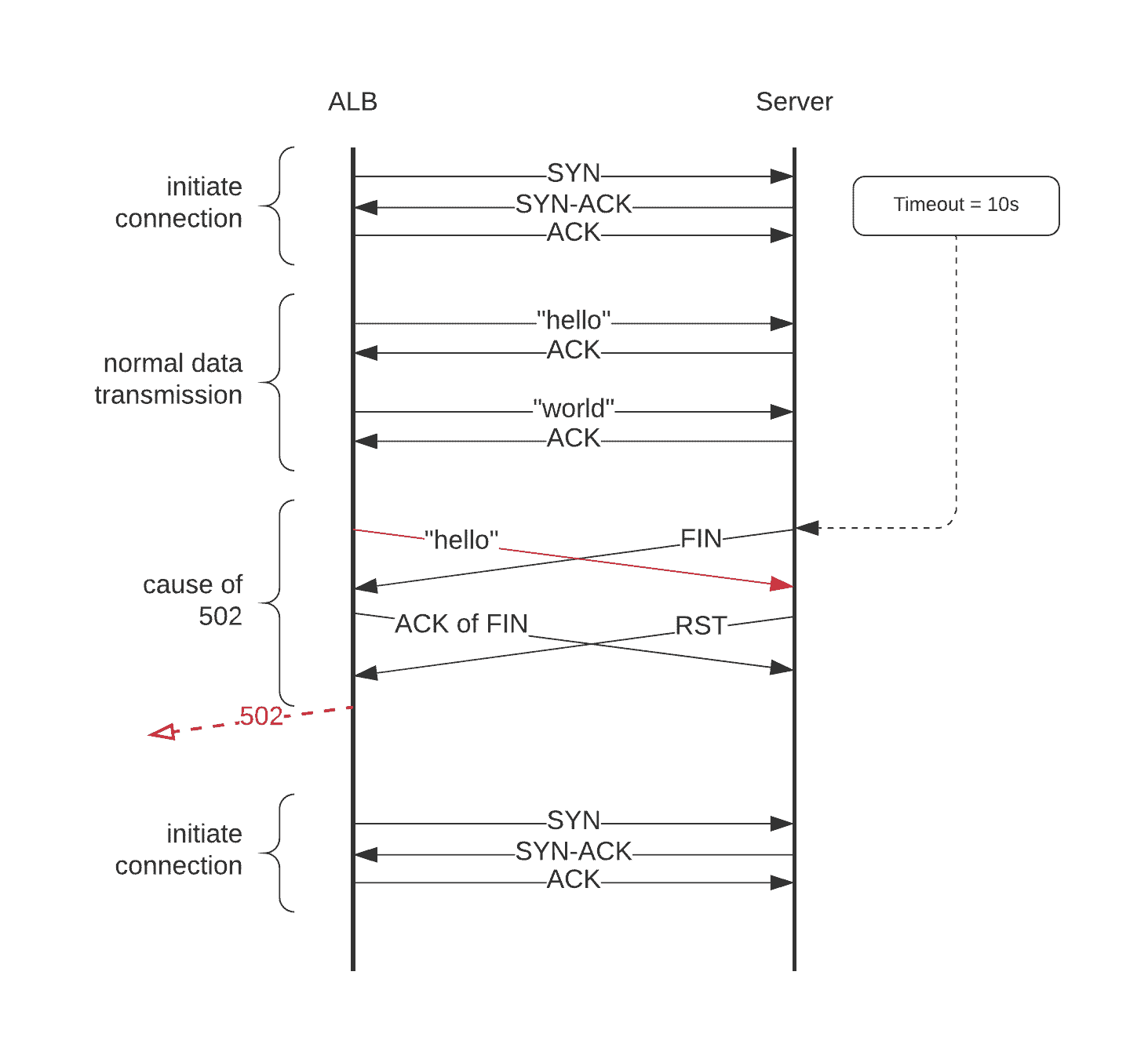
The 502 Bad Gateway error is caused when the ALB sends a request to a service at the same time that the service closes the connection by sending the FIN segment to the ALB socket. The ALB socket receives FIN, acknowledges, and starts a new handshake procedure.
Meanwhile, the socket on the service side has just received a data request referencing the previous (now closed) connection. Because it can’t handle it, it sends an RST segment back to the ALB, and then the ALB returns a 502 to the user.
The diagram and table below show what happens between sockets of the ALB and the Server.
Socket communication segments between the Application Load Balancer and the Server. You can imagine the Client on the left.
Table of segments sent between the Application Load Balancer and the Server.
How to fix 502 errors
It’s fairly simple. Just make sure that the service doesn’t send the FIN segment before the ALB sends a FIN segment to the service. In other words, make sure the service doesn’t close the HTTP Keep-Alive connection before the ALB.
The default timeout for the AWS Application Load Balancer is 60 seconds, so we changed the service timeouts to 65 seconds. Barring two hiccups shortly after deploying, this has totally fixed it.
The actual configuration change
I have included the configuration for common Python and Node server frameworks below. If you are using any of those, you can just copy and paste. If not, these should at least point you in the right direction.
uWSGI (Python)
As a config file:
# app.ini
[uwsgi]
...
harakiri = 65
add-header = Connection: Keep-Alive
http-keepalive = 1
...
Or as command line arguments:
--add-header "Connection: Keep-Alive"
--http-keepalive --harakiri 65
Gunicorn (Python)
As command line arguments:
--keep-alive 65
Express (Node)
In Express, specify the time in milliseconds on the server object.
const express = require('express');
const app = express();
const server = app.listen(80);
server.keepAliveTimeout = 65000
Looking for more tips from engineers and other cybersecurity news? Keep up with our blog and follow us on LinkedIn.
Samson Danziger
Python Backend Engineer