We at Tessian are very passionate about the safety of our customers. We constantly handle sensitive email data to improve the quality of our protection against misdirected emails, exfiltration attempts, spear phishing etc. This means that many of our applications handle data that we can’t afford to have leaked or compromised.
As part of our efforts to keep customer data safe, we take care to encrypt any exceptions we log, as you never know when a variable that has the wrong type happens to contain an email address. This approach allows us to be liberal with the access we give to the logs, while giving us comfort that customer data won’t end up in them. Spark applications are no exception to this rule, however, implementing encryption for them turned out to be quite a journey.
So let us be your guide on this journey. This is a tale of despair, of betrayal and of triumph. It is a tale of PySpark exception encryption.
Problem statement
Before we enter the gates of darkness, we need to share some details about our system so that you know where we’re coming from.
The language of choice for our backend applications is Python 3. To achieve exception encryption we hook into Python’s error handling system and modify the traceback before logging it. This happens inside a function called init_logging() and looks roughly like this:
[codestyle]
def redact_excepthook(exctype, value, traceback):
redacted_exception = format_safe_traceback(exc_info=(exctype, value, traceback))
logger.error("Uncaught exception", traceback=redacted_exception)
def init_logging(...):
...
sys.excepthook = redact_excepthook
[/codestyle]
We use Spark 2.4.4. Spark Jobs are written entirely in Python; consequently, we are concerned with Python exceptions here. If you’ve ever seen a complete set of logs from a YARN-managed PySpark cluster, you know that a single ValueError can get logged tens of times in different forms; our goal will be to make sure all of them are either not present or encrypted.
We’ll be using the following error to simulate an exception raised by a Python function handling sensitive customer information:
[codestyle]
raise ValueError("a@a.com is an email address!!!")
[/codestyle]
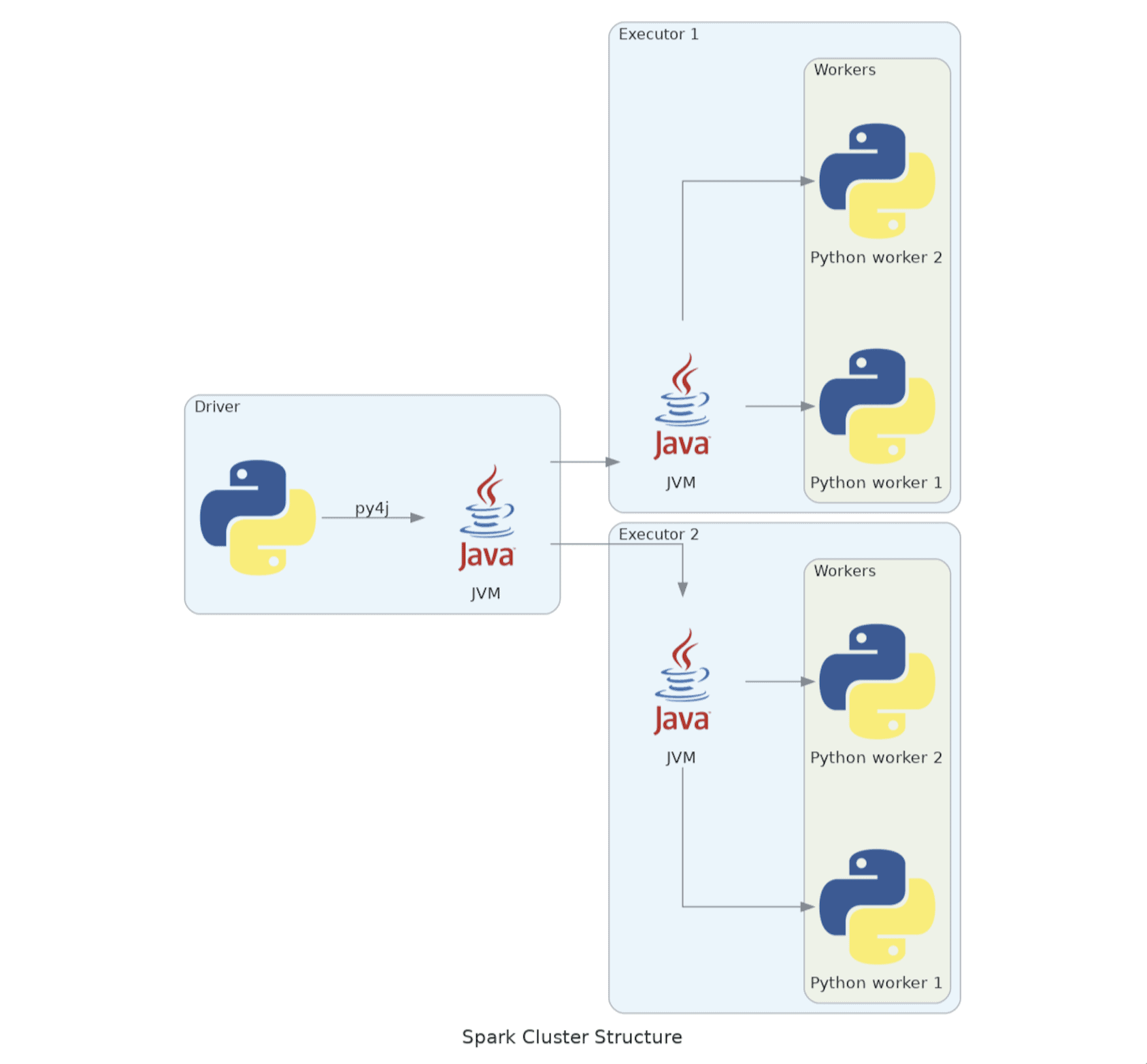
Looking at this, we can separate the problem into 2 parts: the driver and the executors.
The executors
Let’s start with what we initially (correctly) perceived to be the main issue. Spark Executors are a fairly straightforward concept until you add Python into the mix. The specifics of what’s going on inside are not often talked about and are relevant to the discussion at hand, so let’s dive in.
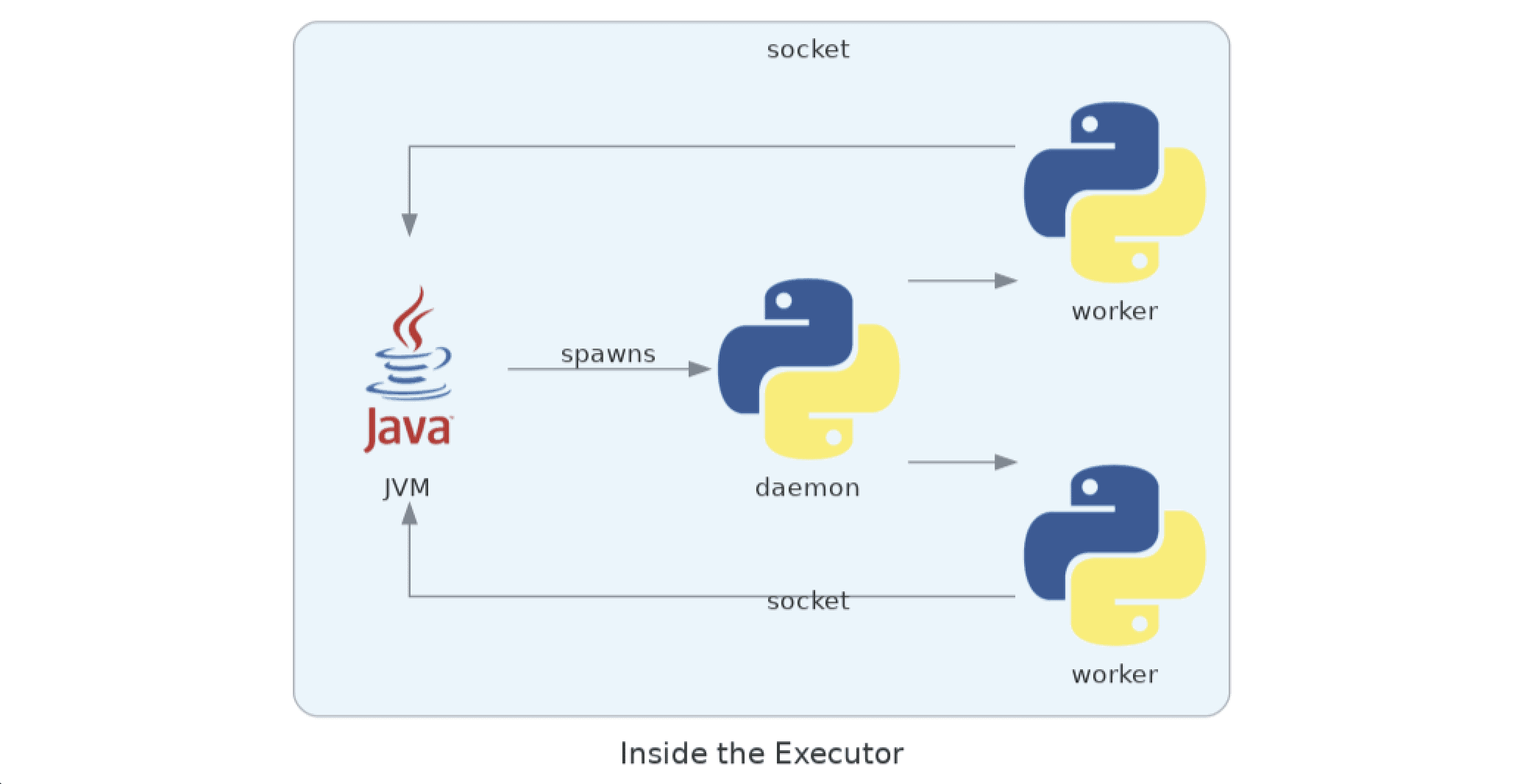
All executors are actually JVMs, not python interpreters, and are implemented in Scala. Upon receiving Python code that needs to be executed (e.g. in rdd.map) they start a daemon written in Python that is responsible for forking the worker processes and supplying them with means of talking to the JVM, via sockets.
The protocol here is pretty convoluted and very low-level, so we won’t go into too much depth. What will be relevant to us are two details; both have to do with communication between the driver and the JVM:
- The JVM executor expects the daemon to open a listening socket on the loopback interface and communicate the port back to it via stdout
- The worker code contains a general try-except that catches any errors from the application code and writes the traceback to the socket that’s read by the JVM
Point 2 is how the Python exceptions actually get to the executor logs, which is exactly why we can’t just use init_logging, even if we could guarantee that it was called: Python tracebacks are actually logged by Scala code!
How is this information useful? Well, you might notice that the daemon controls all Python execution, as it spawns the workers. If we can make it spawn a worker that will encrypt exceptions, our problems are solved. And it turns out Spark has an option that does just that: spark.python.daemon.module. This solution actually works; the problem is it’s incredibly fragile:
- We now have to copy the code of the driver, which makes spark version updates difficult
- Remember, it communicates the port to the JVM via stdout. Anything else written to stdout (say, a warning output by one of the packages used for encryption) destroys the executor:
[codestyle]
ERROR Executor: Exception in task 3.1 in stage 0.0 (TID 7)
org.apache.spark.SparkException:
Bad data in my_daemon's standard output. Invalid port number:
1094795585 (0x41414141)
Python command to execute the daemon was:
python36 -m my_daemon
Check that you don't have any unexpected modules or libraries in
your PYTHONPATH:
......
Also, check if you have a sitecustomize.py module in your python path,
or in your python installation, that is printing to standard output
at org.apache.spark.api.python.PythonWorkerFactory.startDaemon(PythonWorkerFactory.scala:232)
...
[/codestyle]
As you can probably tell by the level of detail here, we really did think we could do the encryption on this level. Disappointed, we went one level up and took a look at how the PythonException was handled in the Scala code.
Turns out it’s just logged on ERROR level with the Python traceback received from the worker treated as the message. Spark uses log4j, which provides a number of options to extend it; Spark, additionally, provides the option to override log processing using its configuration.
Thus, we will have achieved our goal if we encrypted the messages of all exceptions on log4j level. We did it by creating a custom RealEncryptExceptionLayout class that simply calls the default one unless it gets an exception, in which case it substitutes it with the one with an encrypted message. Here’s how it broadly looks:
[codestyle]
public class RealEncryptExceptionLayout extends PatternLayout {
public String format(LoggingEvent event) {
ThrowableInformation throwableInformation = event.getThrowableInformation();
// Not an exception, use the standard log layout
if (throwableInformation == null) {
return super.format(event);
}
Throwable originalThrowable = throwableInformation.getThrowable();
// Implementation classified, serious stuff
return encryptExceptionAndFormat(event, encryptedException);
}
/**
* This layout is specifically created to handle throwables. Thus, return false.
* @return false
*/
@Override
public boolean ignoresThrowable() {
return false;
}
}
[/codestyle]
To make this work we shipped this as a jar to the cluster and, importantly, specified the following configuration:
[codestyle]
log4j.appender.console.layout=com.tessian.spark_encryption.RealEncryptExceptionLayout
[/codestyle]
And voila!
The driver: executor errors by way of Py4J
Satisfied with ourselves, we decided to grep the logs for the error before moving on to errors in the driver. Said moving on was not yet to be, however, as we found the following in the driver’s stdout:
[codestyle]
Traceback (most recent call last):
...
Exception: Py4JJavaError: An error occurred while calling z:org.apache.spark.api.python.PythonRDD.collectAndServe.
: org.apache.spark.SparkException: Job aborted due to stage failure: Task 4 in stage 0.0 failed 4 times, most recent failure: Lost task 4.3 in stage 0.0 (TID 17, ip-10-1-13-199.eu-west-1.compute.internal, executor 1): org.apache.spark.api.python.PythonException: Traceback (most recent call last):
File "/mnt/yarn/usercache/hadoop/appcache/application_1619695256516_0001/container_1619695256516_0001_01_000002/pyspark.zip/pyspark/worker.py", line 377, in main
process()
...
ValueError: a@a.com is an email address!!!
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator.handlePythonException(PythonRunner.scala:456)
...
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:2041)
...
Caused by: org.apache.spark.api.python.PythonException: Traceback (most recent call last):
File "/mnt/yarn/usercache/hadoop/appcache/application_1619695256516_0001/container_1619695256516_0001_01_000002/pyspark.zip/pyspark/worker.py", line 377, in main
process()
...
ValueError: a@a.com is an email address!!!
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator.handlePythonException(PythonRunner.scala:456)
at org.apache.spark.api.python.PythonRunner$$anon$1.read(PythonRunner.scala:592)
[/codestyle]
This not only is incredibly readable but also not encrypted! This exception, as you can very easily tell, is thrown by the Scala code, specifically DAGScheduler, when a task set fails, in this case due to repeated task failures.
Fortunately for us, as illustrated by the diagram above, the driver simply runs python code in the interpreter that, as far as it’s concerned, just happens to call py4j APIs that, in turn, communicate with the JVM. Thus, it’s not meaningfully different from our backend applications in terms of error handling, so we can simply reuse the init_logging() function. If we do it and check the stdout we see that it does indeed work:
[codestyle]
Traceback (most recent call last):
File "/mnt/tmp/spark-a17b2227-1cb8-45db-b23d-f7c1c23cb973/main.py", line 370, in
spark_.range(10).rdd.map(test_logging_func).count()
...
Exception: Py4JJavaError: <encrypted string>
[/codestyle]
The driver: executor errors by way of TaskSetManager
Yes, believe it or not, we haven’t escaped the shadow of the Executor just yet. We’ve seen our fair share of the driver’s stdout. But what about stderr? Wouldn’t any reasonable person expect to see some of those juicy errors there as well?
We pride ourselves on being occasionally reasonable, so we did check. And lo and behold:
[codestyle]
21/04/29 11:22:51 INFO TaskSetManager: Lost task 4.3 in stage 0.0 (TID 17) on ip-10-1-13-199.eu-west-1.compute.internal, executor 1: org.apache.spark.api.python.PythonException (Traceback (most recent call last):
File "/mnt/yarn/usercache/hadoop/appcache/application_1619695256516_0001/container_1619695256516_0001_01_000002/pyspark.zip/pyspark/worker.py", line 377, in main
process()
...
ValueError: a@a.com is an email address!!!
…
21/04/29 11:22:51 INFO DAGScheduler: ResultStage 0 (count at /mnt/tmp/spark-a17b2227-1cb8-45db-b23d-f7c1c23cb973/main.py:370) failed in 4.375 s due to Job aborted due to stage failure: Task 4 in stage 0.0 failed 4 times, most recent failure: Lost task 4.3 in stage 0.0 (TID 17, ip-10-1-13-199.eu-west-1.compute.internal, executor 1): org.apache.spark.api.python.PythonException: Traceback (most recent call last):
File "/mnt/yarn/usercache/hadoop/appcache/application_1619695256516_0001/container_1619695256516_0001_01_000002/pyspark.zip/pyspark/worker.py", line 377, in main
process()
...
ValueError: a@a.com is an email address!!!
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator.handlePythonException(PythonRunner.scala:456)
at org.apache.spark.api.python.PythonRunner$$anon$1.read(PythonRunner.scala:592)
[/codestyle]
Turns out there is yet another component that reports errors from the executors: TaskSetManager; our good friend DAGScheduler also logs this error when a stage crashes because of it. Both of them, however, do this while processing events initially originating in the executors; where does the traceback really come from? In a rare flash of logic in our dark journey, from the Executor class, specifically the run method:
[codestyle]
case t: Throwable =>
logError(s "Exception in $taskName (TID $taskId)", t)
if (!ShutdownHookManager.inShutdown()) {
val(accums, accUpdates) = collectAccumulatorsAndResetStatusOnFailure(taskStartTime)
val serializedTaskEndReason = {
try {
ser.serialize(new ExceptionFailure(t, accUpdates).withAccums(accums))
} catch {
case _:
NotSerializableException =>
// t is not serializable so just send the stacktrace
ser.serialize(new ExceptionFailure(t, accUpdates, false).withAccums(accums))
}
}
setTaskFinishedAndClearInterruptStatus()
execBackend.statusUpdate(taskId, TaskState.FAILED, serializedTaskEndReason)
[/codestyle]
Aha, there’s a Serializer here! That’s very promising, we should be able to extend/replace it to encrypt the exception before actual serialization, right? Wrong. In fact, to our dismay, that used to be possible but was removed in version 2.0.0 (reference: https://issues.apache.org/jira/browse/SPARK-12414).
Seeing as how nothing is configurable at this end, let’s go back to the TaskSetManager and DAGScheduler and note that the offending tracebacks are logged by both of them. Since we are already manipulating the logging mechanism, why not go further down that lane and encrypt these logs as well?
Sure, that’s a possible solution. However, both log lines, as you can see in the snippet, are INFO. To find out that this particular log line contains a Python traceback from an executor we’d have to modify the Layout to parse it. Instead of doing that and risking writing a bad regex (a distinct possibility as some believe a good regex is an animal about as real as a unicorn) we decided to go for a simple and elegant solution. We simply don’t ship the .jar containing the Layout to the driver; like we said, elegant. That turns out to have the following effect:
[codestyle]
log4j:ERROR Could not instantiate class [com.tessian.spark_encryption.RealEncryptExceptionLayout].
java.lang.ClassNotFoundException: com.tessian.spark_encryption.RealEncryptExceptionLayout
...
log4j:ERROR No layout set for the appender named [console].
Command exiting with ret '1'
[/codestyle]
And that’s all that we find in the stderr! Which suits us just fine, as any errors from the driver will be wrapped in Py4J, diligently reported in the stdout and, as we’ve established, encrypted.
The driver: python errors
That takes care of the executor errors in the driver. But the driver is nothing to sniff at either. It can fail and log exceptions just as well, can’t it?
As you have probably already guessed, this isn’t really a problem. After all, the driver is just running python code, and we’re already calling init_logging().
Satisfyingly enough it turns out to work as one would expect. For these errors we again need to look at the driver’s stdout. If we raise the exception in the code executed in the driver (i.e. the main function) the stdout normally contains:
[codestyle]
Traceback (most recent call last):
...
ValueError: a@a.com is an email address!!!
[/codestyle]
Calling init_logging() turns this traceback into:
[codestyle]
Traceback (most recent call last):
…
Exception: ValueError: <encrypted string>
[/codestyle]
Conclusion
And thus our journey comes to an end. Ultimately our struggle has led us to two realizations; neither is particularly groundbreaking, but both are important to understand when dealing with PySpark:
- Spark is not afraid to repeat itself in the logs, especially when it comes to errors.
- PySpark specifically is written in such a way that the driver and the executors are very different.
Before we say our goodbyes we feel like we must address one question: WHY? Why go through with this and not just abandon this complicated project?
Considering that the data our Spark jobs tend to handle is very sensitive, in most cases it is various properties of emails sent or received by our customers. If we give up on encrypting the exceptions, we must accept that this very sensitive information could end up in a traceback, at which point it will be propagated by Spark to various log files. The only real way to guarantee no personal data is leaked in this case is to forbid access to the logs altogether.
And while we did have to descend into the abyss and come back to achieve error encryption, debugging Spark jobs without access to logs is inviting the abyss inside yourself.