This post is part two of Why Confidence Matters, a series about how we improved Defender’s confidence score to unlock a number of important features. You can read part one here.
In this part, we will focus on how we measured the quality of confidence scores generated by Tessian Defender. As we’ll explain later, a key consideration when deciding on metrics and setting objectives for our research was a strong focus on product outcomes.
Part 2.1 – Confidence score fundamentals
Before we jump into the particular metrics and objectives we used for the project, it’s useful to discuss the fundamental attributes that constitute a good scoring model.
1. Discriminatory power
The discriminatory power of a score tells us how good the score is at separating between positive (i.e. phishy) and negative examples (i.e. safe). The chart below illustrates this idea.
For each of two models, the image shows a histogram of the model’s predicted scores on a sample of safe and phish emails, where 0 is very sure the email is safe and 1 is absolutely certain the email is phishing.
While both are generally likely to assign a higher score for a phishing email than a safe one, the example on the left shows a clearer distinction between the most likely score for a phishing vs a safe email.
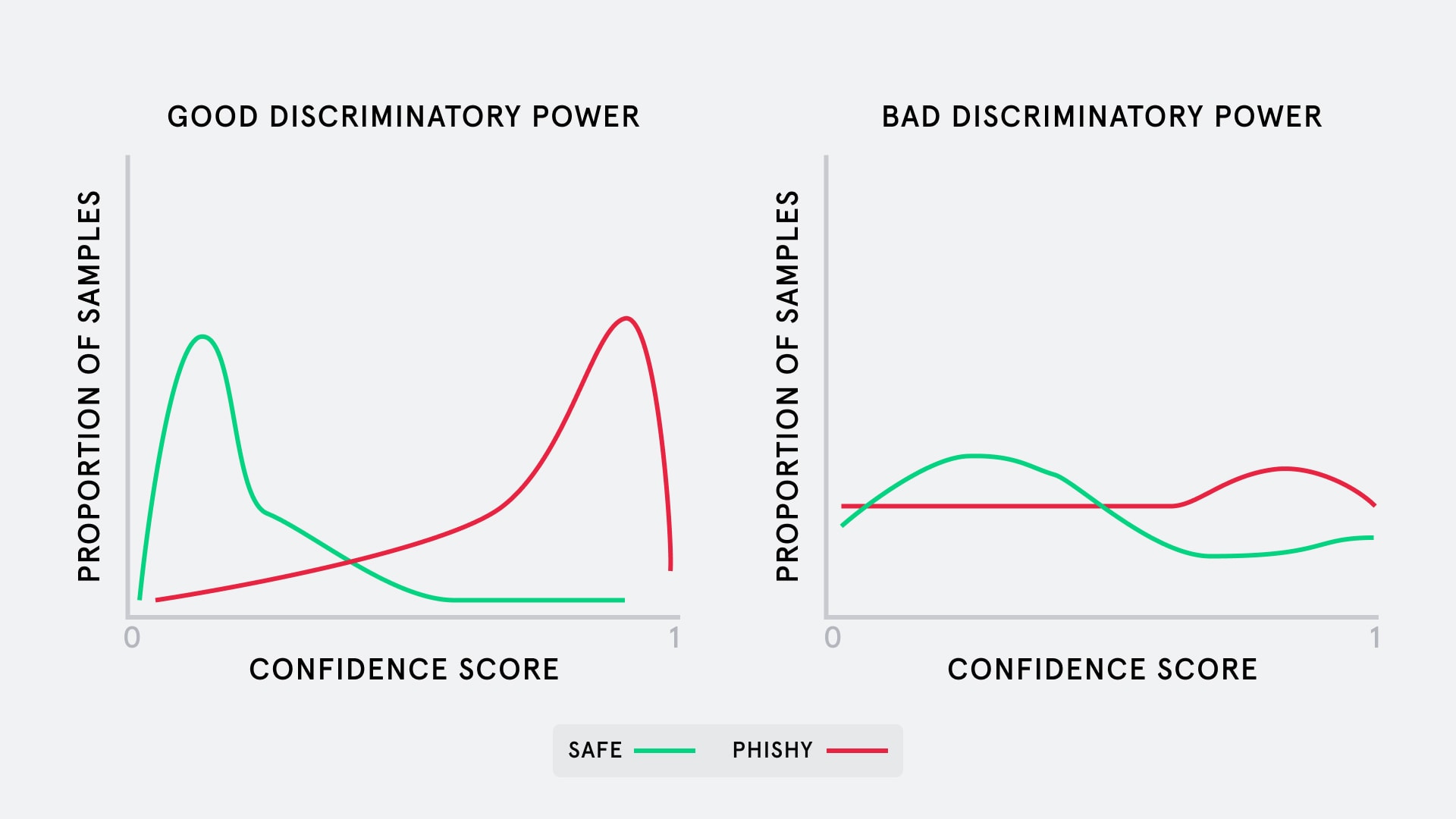
Discriminatory power is very important in the context of phishing because it determines how well we can differentiate between phishing and safe emails, providing a meaningful ranking of flags from most to least likely to be malicious. This confidence also unlocks the ability for Tessian Defender to quarantine emails which are likely to be phishing, and reduce flagging on emails we are least confident about, improving the precision of our warnings.
2. Calibration
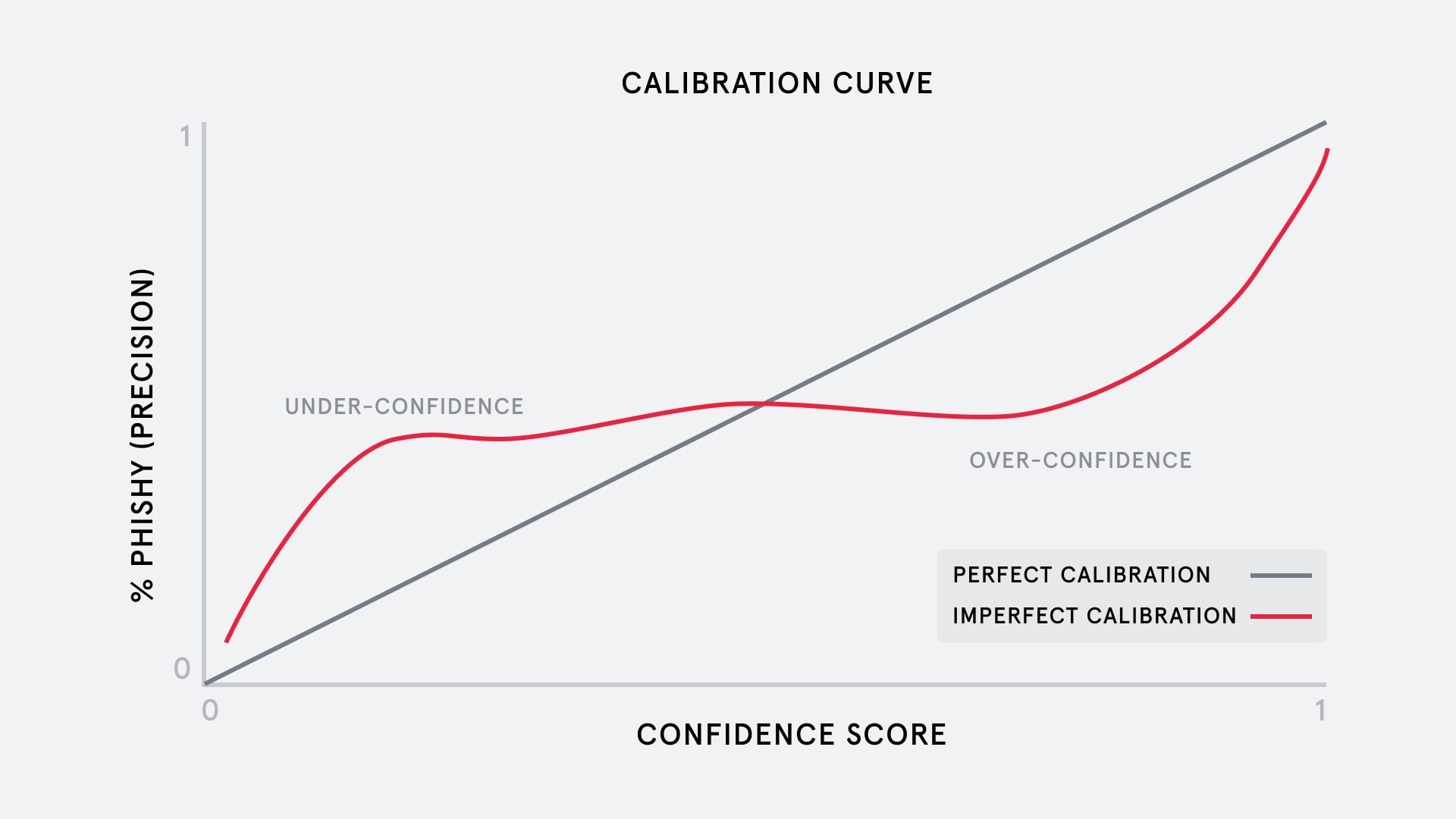
Calibration is another important attribute of the confidence score. A well-calibrated score will reliably reflect the probability that a sample is positive. Calibration is normally assessed using a calibration curve, which looks at the precision of unseen samples across different confidence scores (see below).
The above graph shows two example calibration curves. The gray line shows what a perfectly calibrated model would look like: the confidence score predicted for samples (x-axis) always matches the observed proportion of phishy emails (y-axis) at that score. In contrast, the poorly-calibrated red line shows a model that is underconfident for lower scores (model predicts a lower score than the observed precision) and overconfident for high scores.
From the end-user’s perspective, calibration is especially important to make the score interpretable, and especially matters if the score will be exposed to the user.
3. Consistency
A good score will also generalize well across different cuts of the samples it applies to. For example, in the context of Tessian Defender, we needed a score that would be comparable across different types of phishing. For example, we should expect the scoring to work just as well for Account Takeover (ATO) as it does for a Brand Impersonation. We also had to make sure that the score generalized well across different customers, who operate in different industries and send and receive very different types of emails. For example, a financial services firm may receive a phishing email in the form of a spoofed financial newsletter, but such an email would not appear in the inbox of someone working in the healthcare sector.
Metrics
How do we then quantify the above attributes for a good score? This is where metrics come into play – it is important to design appropriate metrics that are technically robust, yet easily understandable and translatable to a positive user experience.
A good metric for capturing the overall discriminatory power of a model is the area under the ROC curve (AUC-ROC) or the average precision of a model at different thresholds, which capture the performance of the model across all possible thresholds. Calibration can be measured with metrics that estimate the error between the predicted score and true probability, such as the Adaptive Calibration Error (ACE).
While these out-of-the-box metrics are commonly used to assess machine learning (ML) models, there are a few challenges which make it hard to use in a business context.
First, it is quite difficult to explain simply to stakeholders who are not familiar with statistics and ML. For example, the AUC-ROC score doesn’t tell most people how well they should expect a model to behave. Second, it’s difficult to translate real product requirements into AUC-ROC scores. Even for those who understand these metrics, it’s not easy to specify what increase in these scores would be required to achieve a particular outcome for the product.
Defender product-centric metrics
While we still use AUC-ROC scores within the team and compare models by this metric, the above limitations meant that we had to also design metrics that could be understood by everyone at Tessian, and directly translatable to a user’s product feature experience.
First, we defined five simpler-to-understand priority buckets that were easier to communicate with stakeholders and users (from Very Low to Very High). We aimed to be able to quarantine emails in the highest priority bucket, so we calibrated each bucket to the probability of an email being malicious. This makes each bucket intuitive to understand, and allows us to clearly translate to our users’ experience of the quarantine feature.
For the feature to be effective, we also defined a minimum number of malicious emails to prevent reaching the inbox, as a percentage of the company’s inbound email traffic. Keeping track of this metric prevents us from over-optimizing the accuracy of the Very-High bucket at the expense of capturing most of the malicious emails (recall), which would greatly limit the feature’s usefulness.
While good precision in the highest confidence bucket is important, so is accuracy on the lower end of the confidence spectrum.
A robust lower end score will allow us to stop warning on emails we are not confident in, unlocking improvements in overall precision to the Defender algorithm. Hence, we also set targets for accuracy amongst emails in the Very-Low/Low buckets.
For assurance of consistency, the success of this project also depended on achieving the above metrics across slices of data – the scores would have to be good across the different email threat types we detect, and different clients who use Tessian Defender.
Part 2.2 – Our Data: Leveraging User Feedback
After identifying the metrics, we can now look at the data we used to train and benchmark our improvements to the confidence score.Having the right data is key to any ML application, and this is particularly difficult for phishing detection. Specifically, most ML applications rely on labelled datasets to learn from.
We found building a labelled dataset of phishing and non-phishing emails especially challenging for a few reasons:
Data challenges
Phishing is a highly imbalanced problem. On the whole, phishing emails are extremely low in volumes compared to all other legitimate email transactions for the average user. On a daily basis, over 300 billion emails are being sent and received around the world, according to recent statistics. This means that efforts to try to label emails manually will be highly ineffective, like finding a needle in a haystack.
Also, phishing threats and techniques are constantly evolving, such that even thousands of emails labelled today would quickly become obsolete. The datasets we use to train phishing detection models must constantly be updated to reflect new types of attacks.
Email data is also very sensitive by nature. Our clients trust us to process their emails, many of which contain sensitive data, in a very secure manner. For good reasons, this means we control who can access email data very strictly, which makes labelling harder.
All these challenges make it quite difficult to collect large amounts of labelled data to train end-to-end ML models to detect phishing.
User feedback and why it’s so useful
As you may remember from part one of this series, end-users have the ability to provide feedback about Tessian Defender warnings. We collect thousands of these user responses weekly, providing us with invaluable data about phishing.
User responses help address a number of the challenges mentioned above.
First, they provide a continually updated view of changes in the attack landscape. Unlike a static email dataset labelled at a particular point in time, user response labels can capture information about the latest phishing trends as we collect them, day-in and day-out. With each iteration of model retraining with the newest user labels, user feedback is automatically incorporated into the product. This creates a positive feedback loop, allowing the product to evolve in response to users’ needs.
Relying on end-users to label their own emails also helps alleviate concerns related to data sensitivity and security. In addition, end-users also have the most context about the particular emails they receive. Combined with explanations provided by Tessian warnings, they are more likely to provide accurate feedback.
These benefits address all the previous challenges we faced neatly, but it is not without its limitations.
For one, the difference between phishing, spam and graymail is not always clear to users, causing spam and graymail to often be labelled as malicious. Often, several recipients of the same email can also disagree on whether it is malicious. Secondly, user feedback data may not be a uniform representation of the email threat landscape – we often receive more feedback from some clients or certain types of phishing. Neglecting to address this under-representation would result in a model that performs better for some clients, something we absolutely need to avoid in order to ensure consistency in the quality of our product for all new and existing clients.
In the last part of the series Why Confidence Matters, we’ll discuss how we navigated the above challenges, delve deeper into the technical design of the research pipeline used to build the confidence-scoring model, and the impact that this has brought to our customers.
(Co-authored by Gabriel Goulet-Langlois and Cassie Quek)